


세계의 음성 인식 시장 규모는 2025년에 183억 9,000만 달러로 추정되고, 2030년에는 CAGR 22.97%로 성장할 전망이며, 517억 2,000만 달러에 달할 것으로 예측되고 있습니다.

시장 확대는 엣지 인공지능(AI) 칩셋의 급속한 전개, 긴급 통신 네트워크의 현대화에 대한 규제 압력, 고객 인증을 위한 음성 바이오메트릭으로의 기업 이행 등 3가지의 동시 진행력을 반영합니다. 시장 개척의 70.7%는 소프트웨어 개발 키트와 애플리케이션 프로그래밍 인터페이스 플랫폼으로, 2024년에는 클라우드 도입이 62.1%를 차지했기 때문에 현재는 소프트웨어 중심의 아키텍처가 주류가 되고 있습니다. 지역별로는 다국어 인터페이스 수요와 강력한 칩 제조 에코시스템을 배경으로 아시아가 2024년 시장 점유율 32.5%로 선도했습니다. 음성 인식 기술은 여전히 주요 기술의 기둥에서 점유율 81.2%를 차지하고 있지만, 내장형 온 디바이스 처리가 CAGR로 가장 빠른 25%를 달성하였고 클라우드 전용 설계에서 하이브리드형 또는 완전 로컬형 추론 엔진으로의 결정적인 전환을 보여주고 있습니다.
Chipintelli에 따른 14개의 오프라인 AI 스피치 칩과 MediaTek의 MR Breeze ASR 25 모델 출시는 지역 언어에 최적화된 특수 실리콘에 대한 투자가 확대되고 있음을 보여줍니다. 현지화는 낮은 지연을 실현시키고, cloud streaming에 얽힌 프라이버시의 우려를 해결하며, 역사적으로 북미의 hyperscalers에 의존하고 있던 국내 supply chain를 정착시키킵니다. 아시아의 반도체 기업은 이 장점을 활용하여 인도네시아, 베트남, 인도 등 시장에서 코드 전환을 처리하는 턴키 음성 스택을 디바이스 OEM에 제공하여 엣지 추론 혁신에서 이 지역의 리더십을 강화하고 있습니다.
FCC의 새로운 규칙을 통해 미국 통신 사업자는 IP 기반 세션 시작 프로토콜을 통해 911 통화를 라우팅하고, 반경 165m 이하의 잘못된 라우팅을 90% 신뢰도로 차단하며, 실시간 텍스트와 비디오를 지원해야 했습니다. 음성 인식 공급업체는 전국 및 지역의 통신사업자에게 6-12개월 이내에 컴플라이언스 준수 기한이 도래하기 때문에 긴급 서비스 주변에 위치한 벤더는 예측 가능한 수익 증가를 얻을 수 있습니다. 이 의무화는 유럽의 공공 안전 네트워크에 영향을 미칠 가능성이 높은 템플릿을 만들고 작성된 음성 및 메타데이터로 인시던트 데이터를 풍부하게 하는 음성 분석에 대한 대응 가능한 총 수요를 확대합니다.
아프리카의 93개의 방언으로 테스트했는데, 의료기관의 에러율은 25-34%로, 방언 특유의 미세조정이 필요했습니다. NaijaVoices의 1,800시간 데이터 세트는 Whisper 모델의 단어 오류율을 75.86% 줄였지만, 문화적으로 풍부한 코퍼스를 만드는 비용과 복잡성은 상업적 전개를 늦추고 있습니다. Intron Health의 160만 달러의 시드 라운드는 투자자들이 이 문제를 인식하고 있음을 보여주지만, 동시에 현지화된 모델 훈련에 대한 자금 수요도 부각되고 있습니다.
클라우드 전개는 2024년 세계 매출의 62.1%를 차지했으며, 기업이 신속한 롤아웃, 지속적인 모델 업데이트, 폭넓은 언어 커버리지를 선호하기 때문에 이 점유율은 확대될 것으로 예측됩니다. 금융기관 및 의료 제공자는 원시 레코딩을 온프레미스에 두고 모델 트레이닝 인사이트를 클라우드에 풀링하는 하이브리드 아키텍처를 선택하는 경향이 강해지고 있습니다. 이 접근 방식은 컴플라이언스와 집계된 학습을 통한 성능 향상의 균형을 이룹니다. 따라서 온프레미스의 도입은 소블린 데이터 요구사항에 여전히 적합하며, 이 부문이 2030년까지 2자리 성장을 유지하는 이유가 되었습니다.
고가용성 음성 엔드포인트에 대한 수요는 하이퍼스케일러에게 턴키 API를 노출하도록 촉구하고 있습니다. 그 결과 중견기업의 경우 총소유비용이 낮아지고 독립개발자에게는 진입 장벽이 낮아집니다. 그 결과, 음성 인식 시장 도입을 위한 애플리케이션 퍼널이 확산되고, 소비자 디바이스뿐만 아니라 프로세스 자동화, 물류, 현장 서비스 워크플로우까지 확대되고 있습니다. 클라우드 구현의 음성 인식 시장 규모는 신규 워크로드와 기존 전개의 확대를 반영하여, 2030년까지 320억 달러에 접근할 것으로 예측됩니다.
소프트웨어 플랫폼은 2024년 세계 지출액의 70.7%를 차지했으며, 독점 하드웨어에서 모듈화된 개발자 친화적인 도구로 업계가 축발을 옮기는 것을 뒷받침하는 결정적인 마진이 되고 있습니다. RESTful API와 미리 구축된 언어 모델을 사용할 수 있게 되었기 때문에 많은 이용 사례로 특주 실리콘이 불필요하게 되었습니다. 서비스는 도메인 튜닝, 악센트 적응, 보안 컴플라이언스를 전문 벤더에 의뢰하는 기업이 증가하여 CAGR 23.7%가 되었습니다.
하드웨어는 자동차 인포테인먼트 및 산업용 헤드 마운트 디스플레이와 같이 엣지 레이턴시 및 오프라인 가용성, 음향 빔포밍이 중요한 상황에서 중요성을 유지합니다. 그러나 대부분의 신규 진출기업들은 platform-as-a-service 서비스를 활용하여 하드웨어를 피하고 있으며 수평 지향 소프트웨어 공급자와 수직 통합 하드웨어 전문가 간의 격차가 커지고 있음을 보여줍니다.
음성 인식 시장은 전개 모드별(클라우드, 온프레미스), 컴포넌트별(소프트웨어 및 SDK, 하드웨어, 서비스), 기술별(음성 인식, 음성 생체 인증, 엣지 음성 AI), 장치 유형별(스마트폰, 스마트 스피커, 자동차, 웨어러블, POS), 용도별(인증, 음성 검색, 기타), 최종 사용자 산업별(자동차, BFSI 등), 지역별로 구분됩니다. 시장 예측은 금액(달러)으로 제공됩니다.
아시아는 2024년 매출의 32.5%를 차지했으며, 이 지역의 반도체 생산 능력과 언어의 다양성을 반영하고 있습니다. 일본의 동남아시아 언어 모델에 대한 자금 제공 이니셔티브는 그 예입니다. 북미는 여전히 기술의 조기 도입 거점이지만, 적극적인 현지화 및 디바이스 비용의 저하에 의해 아시아에 점유율을 빼앗겼습니다. 유럽은 자동차와 BFSI의 주제별 채용의 영향을 받아 꾸준히 성장했습니다.
중동은 걸프 스마트 시티 프로그램이 시민 서비스 인프라에 대화형 키오스크를 통합했기 때문에 가장 빠른 23.1%의 연평균 복합 성장률(CAGR)을 보였습니다. 남미는 전자상거래 음성 검색 및 은행 인증으로 10%대 중반의 성장을 기록하고 있습니다. 아프리카는 악센트의 다양성이 범용 모델을 복잡하게 하기 때문에 지연에 직면하고 있습니다. 그러나 기증자 자금을 통한 언어 프로젝트와 통신 업그레이드는 2027년 이후 잠재 수요를 파악할 수 있습니다.
The global voice recognition market size reached USD 18.39 billion in 2025 and is forecast to advance at a 22.97% CAGR to attain USD 51.72 billion by 2030.
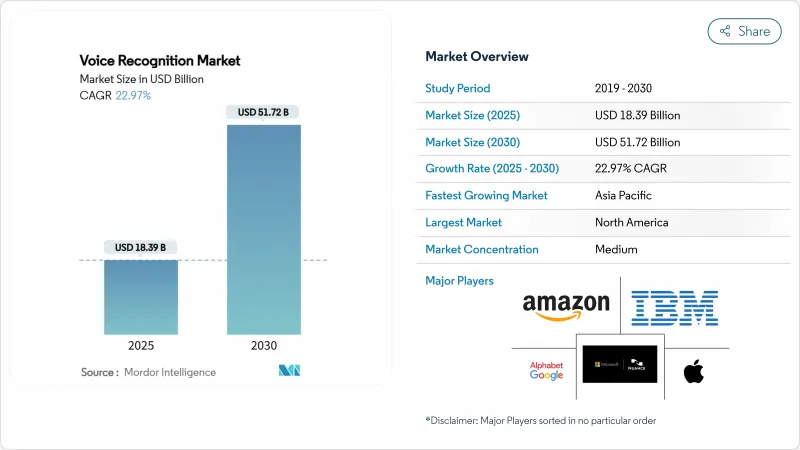
Market expansion reflects three concurrent forces: the rapid roll-out of edge artificial intelligence (AI) chipsets, regulatory pressure for modernising emergency communications networks, and enterprise migration to voice biometrics for customer authentication. Software-centric architectures now dominate because 70.7% of market value sits in software development kits and application-programming-interface platforms, while cloud deployment accounts for 62.1% of implementations in 2024. Regionally, Asia led with 32.5% market share in 2024 on the back of multilingual interface demand and strong chip manufacturing ecosystems; speech recognition technology remained the principal technology pillar with 81.2% share, yet embedded on-device processing delivered the fastest 25% CAGR, showing a decisive shift from cloud-only designs to hybrid or fully local inference engines.
The release of 14 offline AI speech chips by Chipintelli and MediaTek's MR Breeze ASR 25 model signal escalating investment in specialised silicon optimised for regional languages. Localisation delivers lower latency, resolves privacy concerns tied to cloud streaming, and entrenches domestic supply chains that historically depended on North American hyperscalers. Asian semiconductor firms leverage this advantage to offer device OEMs turnkey voice stacks that handle code-switching in markets such as Indonesia, Vietnam, and India, reinforcing the region's leadership in edge inference innovation.
New FCC rules obligate US carriers to route 911 calls via IP-based Session Initiation Protocol, cut misrouting below a 165-meter radius at 90% confidence, and support real-time text and video. Voice recognition vendors positioned around emergency services gain a predictable revenue ramp because compliance deadlines fall within a 6-12-month horizon for nationwide and regional operators. The mandate creates a template likely to influence European public safety networks, expanding total addressable demand for voice analytics that enrich incident data with transcribed speech and metadata.
Tests across 93 African accents showed medical entity error rates that still required 25-34% refinement via accent-specific fine-tuning. NaijaVoices' 1,800-hour dataset cut word-error rates for Whisper models by 75.86%, but the cost and complexity of curating culturally rich corpora slow commercial roll-outs. Intron Health's USD 1.6 million seed round underlines investor recognition of the problem, yet it also highlights the capital demands of localised model training.
Other drivers and restraints analyzed in the detailed report include:
For complete list of drivers and restraints, kindly check the Table Of Contents.
Cloud delivery generated 62.1% of global revenue in 2024, and that share is projected to widen as enterprises prioritise rapid rollout, continuous model updates, and broad language coverage. Financial institutions and healthcare providers increasingly select hybrid architectures that keep raw recordings on premises but pool model-training insights in the cloud. The approach balances compliance with the performance gains of aggregated learning. On-premise deployments therefore remain relevant for sovereign-data mandates, explaining why the segment still posts double-digit growth through 2030.
Demand for high-availability voice endpoints has pushed hyperscalers to expose turnkey APIs. Consequently, total cost of ownership falls for mid-sized enterprises, and barriers to entry lower for independent developers. The result is a wider application funnel for voice recognition market adoption, extending beyond consumer devices into process automation, logistics, and field-service workflows. The voice recognition market size for cloud implementations is set to approach USD 32 billion by 2030, reflecting both new workloads and expansion of existing deployments.
Software platforms captured 70.7% of global spend in 2024, a decisive margin that underpins the industry's pivot from proprietary hardware to modular, developer-friendly tooling. The availability of RESTful APIs and pre-built language models removes the need for bespoke silicon in many use cases. Services, although representing a smaller base, rise at 23.7% CAGR as enterprises engage specialist vendors for domain tuning, accent adaptation, and security compliance.
Hardware maintains relevance where edge latency, offline availability, or acoustic beam-forming matter, such as in automotive infotainment or industrial head-mounted displays. Yet most new entrants bypass hardware by consuming platform-as-a-service offerings, illustrating an expanding gap between horizontally oriented software providers and vertically integrated hardware specialists.
Voice Recognition Market is Segmented by Deployment (Cloud, On-Premise), Component (Software/SDK, Hardware, Services), Technology (Speech Recognition, Voice Biometrics, Edge Voice AI), Device Type (Smartphones, Smart Speakers, Automotive, Wearables, POS), Application (Authentication, Voice Search, and More), End-User Vertical (Automotive, BFSI, and Morel), and by Geography. Market Forecasts in Value (USD).
Asia generated 32.5% of 2024 turnover, reflecting the region's semiconductor capacity and linguistic diversity. Domestic policy supports AI acceleration; Japan's initiative to fund Southeast Asian language models is one example. North America remains technology's early-adopter hub but ceded share to Asia because of aggressive localisation and lower device costs. Europe grew steadily, influenced by automotive and BFSI thematic adoption.
The Middle East exhibits the quickest 23.1% CAGR as Gulf smart-city programmes embed conversational kiosks in citizen-services infrastructure. South America records mid-teens growth from e-commerce voice search and banking authentication. Africa faces a lag because accent diversity complicates universal models; however, donor-funded language projects and telecom upgrades may unlock latent demand from 2027 onward.